SpeciFix: Automatic Program Repair by Fixing Contracts
SpeciFix automatically proposes contract changes as fixes to program faults. For information about automatic generation of fixes to implementations, please visit the homepage of the AutoFix tool.
Overview
While most debugging techniques focus on patching implementations, there are numerous bugs whose most appropriate corrections consist in fixing the specification to prevent invalid executions---such as to define the correct input domain of a function. We present here a fully automatic technique that fixes bugs by proposing changes to contracts (simple executable specification elements such as pre- and postconditions). The technique relies on dynamic analysis to understand the source of buggy behavior, to infer changes to the contracts that emend the bugs, and to validate the changes against general usage. We have implemented the technique in a tool called SpeciFix, which works on programs written in Eiffel, and evaluated it on 44 bugs found in standard data-structure libraries. Manual analysis by human programmers found that SpeciFix suggested repairs that are directly deployable for 25% of the faults; in most cases, these contract repairs were preferred over fixes for the same bugs that change the implementation.Example
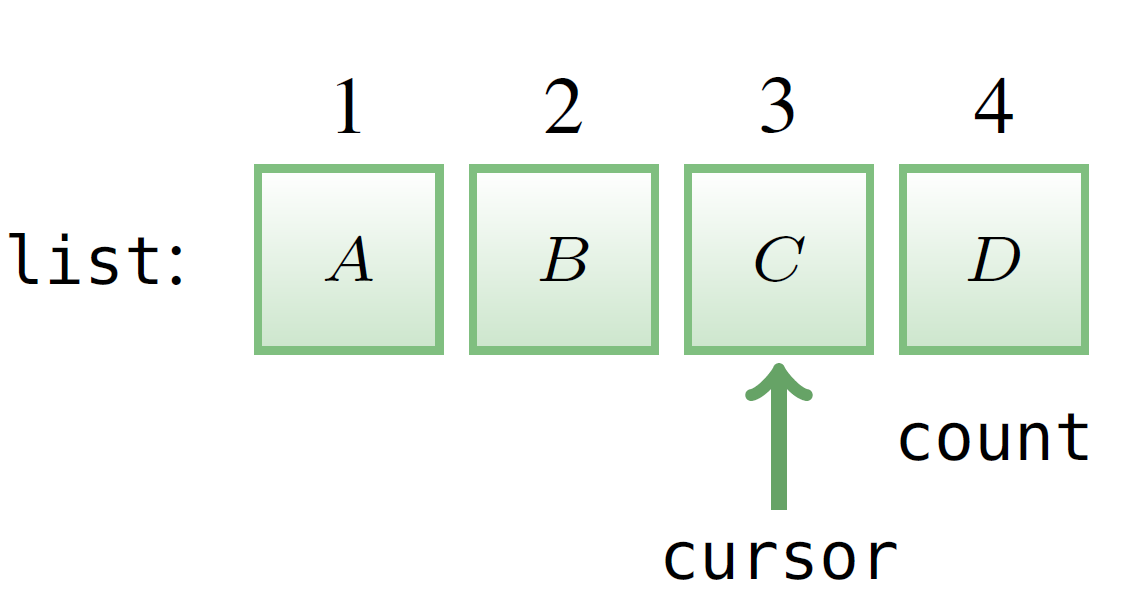
Let us briefly demonstrate how SpeciFix works using an example. The example targets a bug of routine (method) duplicate in class CIRCULAR,which is the standard Eiffel library implementation of circular array-based lists. To understand the bug, Figure 1 illustrates a few details of CIRCULAR's API. Lists are numbered from index 1 to index count (an attribute denoting the list length), and include an internal cursor that may point to any element of the list. Routine duplicate takes a single integer argument n, which denotes the number of elements to be copied; called on a list object list, it returns a new instance of CIRCULARwith at most n elements copied from list starting from the position pointed to by cursor. Since we are dealing with circular lists, the copy wraps over to the first element. For example, calling duplicate (3) on the list in Figure 2 returns a fresh list with elements <C, D, A>|
1
class
CIRCULAR
[G]
2 3 make (m: INTEGER) 4 require m >= 1 5 do ... end 6 7 duplicate (n: INTEGER): CIRCULAR [G] 8 do 9 create Result.make (count) 10 ... 11 end 12 13 count: INTEGER -- Length of list |
 |
|
| Figure 1. Some implementation details of CIRCULAR. | Figure 2. A circular list of class CIRCULAR: the internal cursor points to the element C at index 3. |
procedure (constructor) make on line 9 allocates space for a list with count elements; this is certainly sufficient, since Result cannot contain more elements than the list that is duplicated. However, CIRCULAR’s creation procedure make includes a precondition (line 4 in Figure 1) that only allows allocating lists with space for at least one element (require m ≥ 1). This sets off a bug when duplicate is called on an empty list: count is 0, and hence the call on line 9 triggers a violation of make’s precondition. Testing tools such as AutoTest detect this bug automatically by providing a concrete test case that exposes the discrepancy between implementation and specification.
|
make (m:
INTEGER) require m ≥ 1 duplicate (n: INTEGER):CIRCULAR [G] do if count > 0 then create Result.make (count) else create Result.make (1) end ... |
make (m:
INTEGER) require m ≥ 1 duplicate (n: INTEGER):CIRCULAR [G] require count > 0 do create Result.make (count) ... |
make (m: INTEGER) require m ≥ 0 duplicate (n: INTEGER): CIRCULAR [G] do create Result.make (count) ... |
| (a) Patching the implementation. | (b) Strengthening the specification. | (c) Weakening the specification. |
| Figure 3: Three different fixes for the bug of Figure 1. | ||
How should we fix this bug? Figure 3 shows three different possible repairs, all of which we can generate completely automatically. An obvious choice is patching duplicate’s implementation as shown in Figure 3a: if count is 0 when duplicate is
invoked, allocate Result with space for one element; this satisfies make’s precondition in all cases. Our AutoFix tool targets fixes of implementations and in fact suggests the patch in Figure 3a. The fix that changes the implementation is acceptable, since it makes duplicate run correctly, but it is not entirely satisfactory: CIRCULAR’s implementation looks perfectly adequate, whereas the ultimate source of failure seems to be incorrect or inadequate specification. A straightforward fix is then adding a precondition to duplicate that only allows calling it on non-empty lists. Figure 3b shows such a fix, which strengthens duplicate’s precondition thus invalidating the test case exposing the bug. The strengthening fix has the advantage of being textually simpler than the implementation fix, and hence also probably simpler for programmers to understand. However, both fixes in Figures 3a and 3b are partial, in that they remove the source of faulty behavior in duplicate but they do not prevent similar faults—deriving from calling make with m = 0—from happening. A more critical issue with the specification-strengthening fix in Figure 3b is that it may break clients of CIRCULAR that rely on the previous weaker precondition. There are cases—such as when computing the maximum of an empty list—where strengthening produces the most appropriate fixes; in the running example, however, strengthening arguably is not the optimal strategy.
A look at make’s implementation (not shown in Figure 1) would reveal that the creation procedure’s precondition m ≥ 1 is unnecessarily restrictive, since the routine body works as expected also when executed with m = 0. This suggests a fix that weakens make’s precondition as shown in Figure 3c. This is arguably the most appropriate correction to the bug of duplicate: it is very simple, it fixes the specific bug as well as similar ones originating in creating an empty list, and it does not invalidate any clients of CIRCULAR’s API. The SpeciFix tool described in this paper generates both specification fixes in Figures 3b and 3c but ranks the weakening fix higher than the strengthening one. More generally, SpeciFix outputs specification-strengthening fixes only when they do not introduce bugs in available tests, and it always prefers the least restrictive fixes among those that are applicable.
How does SpeciFix Work?
SpeciFix works completely automatically: its only input is an Eiffel program annotated with simple contracts (pre- and postconditions and class invariants) which constitute its specification. After going through the steps described in the rest of this section, SpecFix’s final output is a list of fix suggestions for the bugs in the input program. Figure 4 gives an overview of the components of the SpeciFix technique. SpeciFix is based on dynamic analysis, and hence it characterizes correct and incorrect behavior by means of passing and failing test cases. To provide full automation, we use the random testing framework AutoTest to generate the tests used by SpeciFix. The core of the fix generation algorithm applies two complementary strategies: weaken (i.e., relax) a violated contract if it is needlessly restrictive; or strengthen an existing contract to rule out failure-inducing inputs. SpeciFix produces candidate fixes using both strategies, possibly in combination. To determine whether the weaker or stronger contracts remove all faulty behavior in the program, SpeciFix runs candidate fixes through a validation phase based on all available tests. To avoid overfitting, some tests are generated initially but used only in the validation phase (and not directly to generate fixes). If multiple fixes for the same fault survive the validation phase, SpeciFix outputs them to the user ordered according to the strength of their new contracts: weaker contracts are more widely applicable, and hence are ranked higher than more restrictive stronger contracts
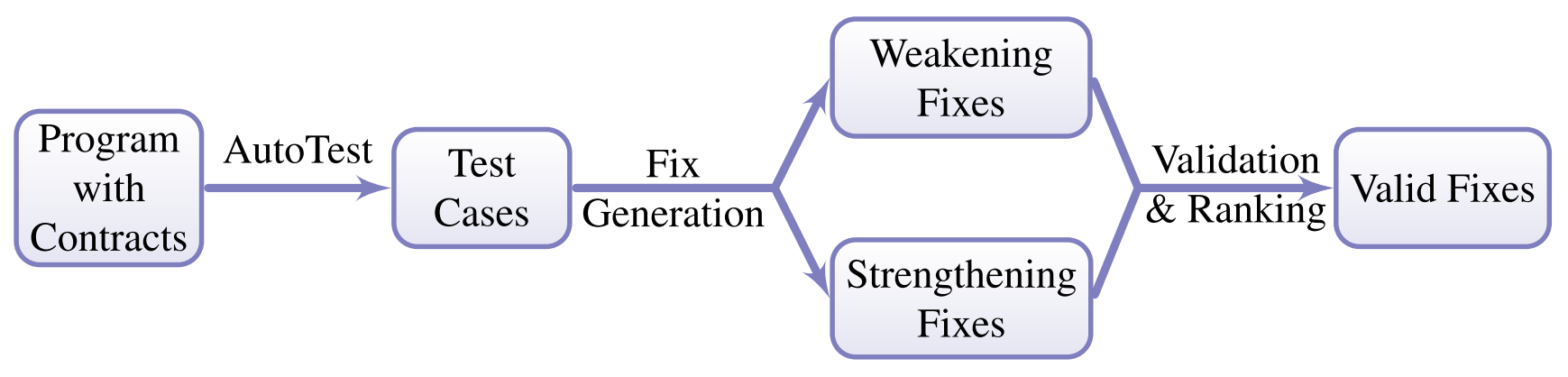 |
| Figure 4. An overview of how SpeciFix works. Running AutoTest on an input Eiffel program with contracts produces a collection of test cases that characterize correct and incorrect behavior. With the goal of correcting faulty behavior, the fix generation algorithm builds candidate fixes using two strategies: weakening and strengthening the existing contracts. The candidate fixes enter a validation phase where they must pass all valid test cases; valid fixes are ranked—the weaker the new contracts the higher the ranking—and presented as output. |
Experiment with SpeciFix
We performed a preliminary evaluation of the behavior of SpeciFix by applying it to 44 bugs of production software. The overall goal of the evaluation is corroborating the expectation that, for bugs whose “most appropriate” correction is fixing the specification, SpeciFix can produce repair suggestions of good quality. A more detailed evaluation taking into account aspects such as robustness and readability of the produced fixes belongs to future work.All the experiments ran on a Windows 7 machine with a 2.6 GHz Intel 4-core CPU and 16 GB of memory. We selected 10 of the most widely used data-structure classes of the EiffelBase (rev. 92914) and Gobo (rev. 91005) libraries—the two major Eiffel standard libraries. We ran AutoTest for one hour on each of the 10 classes. This automatic testing session found 44 unique faults consisting of pre- or postcondition violations. We ran SpeciFix on each of these faults individually, using half of the test cases (generated for each fault in the one-hour session) to generate the fixes and the other half in the validation phase. SpeciFix produced valid fixes for 42 faults and proper fixes (i.e. fixes that correct the fault without introducing new faults) for 11. The average figures per fault are: 106.4 minutes of testing time and 7.2 minutes of fixing time (minimum: 4.1 minutes, maximum: 30 minutes, median 6.2 minutes). The testing time dominates since AutoTest operates randomly and thus generates many test cases that will not be used (such as passing tests of routines without faults).
Downloads
SpeciFix is part of the Eve integrated verification environment, the research branch of EiffelStudio
- Instructions to install and compile Eve
- Source code
- SpeciFix: check out revision 93140 from svn repository
- Test cases
- Test cases for reproducing the faults and generating the fixes are available here
- Test cases for features with relaxed contracts are available here
- Fixing results
Funding
The following subjects have contributed to funding the AutoTest project:- ERC grant CME/291389
- SNF grants LSAT/200020-134974 and ASII/200021-134976
- Hasler-Stiftung grant #2327